Einleitung
Dieser Leitfaden dient als Ihr Wegweiser, um Ihnen einen klaren und verständlichen Überblick über die notwendigen Schritte zu geben, um LLMs mit Ihren eigenen Daten zu verbinden.
Sie müssen kein Programmierer sein, um die folgenden Inhalte zu verstehen. Der Zweck dieses Artikels ist es, Ihnen ein solides Verständnis dafür zu vermitteln, was notwendig ist, um die beeindruckenden Möglichkeiten der LLMs in Ihrem Unternehmen zu nutzen.
Die Integration von LLMs erfordert diese fünf Kernschritte:
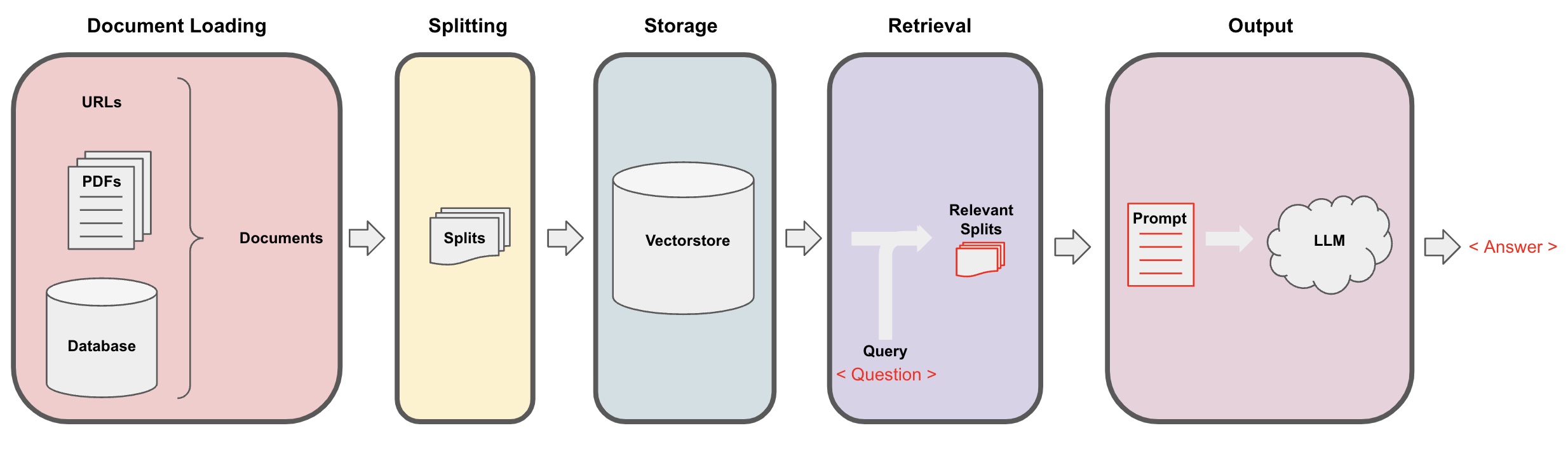
Daten Laden: Ihre Unternehmensdaten in ein System laden, das sie interpretieren kann.
Texte zerteilen: Lange Textdokumente in kleinere, handhabbare Teile unterteilen.
Texte speichern: Die Textstücke werden in einem Speichersystem abgelegt, das die Suche nach ähnlichen Texten ermöglicht.
Relevante Informationen finden: Nach Textstücken suchen, die die Antwort auf eine gestellte Frage enthalten könnten.
Antwort generieren: Eine klare und präzise Antwort basierend auf den gefundenen Informationen formulieren.
In diesem Prozess spielt LangChain eine entscheidende Rolle. Als spezialisierte Technologie erleichtert LangChain die Integration von LLMs in Ihre Systeme. Es wurde entwickelt, um Ihre Unternehmensdaten mit fortschrittlichen Sprachmodellen wie ChatGPT zu verknüpfen, und ermöglicht so eine einfachere Implementierung, Anpassung und Skalierung.
Schritt 1: Daten laden
Beim Laden von Daten geht es darum, alle wichtigen Unternehmensinformationen in ein System zu bringen, das sie verstehen kann. Dies ist der erste und entscheidende Schritt, um LLMs in Ihrem Unternehmen zu nutzen.
Sie können viele verschiedene Arten von Daten laden, darunter:
APIs
Datenbanken
CSV & Excel
Textdateien
HTML
JSON
Markdown
PDF
Egal, ob es sich um Textdokumente, Tabellen oder Webseiten handelt, diese Daten müssen in einem Format gesammelt werden, das das System interpretieren kann. Hierfür gibt es spezialisierte Werkzeuge, die das Extrahieren und Speichern von Texten erleichtern.
Das Laden der Daten legt den Grundstein für alles Weitere. Es sorgt dafür, dass das System die Informationen hat, die es braucht, um später klare und präzise Antworten zu liefern.
Technologie dahinter
Document Loaders: Diese Werkzeuge sind speziell dafür entwickelt, Texte aus verschiedenen Quellen wie PDFs, Websites und Datenbanken zu extrahieren.
Beispielcode (laden einer Webseite):
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://example.com/document")
data = loader.load()
Schritt 2: Text zerteilen
Lange Textdokumente können schwer zu handhaben sein, besonders wenn Sie viele Informationen auf einmal analysieren möchten. In diesem Schritt werden diese langen Dokumente in kleinere, leichter zu handhabende Teile unterteilt.
Stellen Sie sich vor, Sie haben ein großes Buch, und Sie müssen schnell einen bestimmten Abschnitt finden. Wenn Sie das Buch in Kapitel unterteilen, wird es viel einfacher, genau das zu finden, was Sie brauchen. Das Zerteilen von Texten funktioniert auf die gleiche Weise.
Der Trick hierbei ist, die Texte so zu zerteilen, dass die Teile, die zusammengehören, auch zusammenbleiben. Sie möchten nicht, dass Sätze oder Gedanken in der Mitte abgeschnitten werden. Gleichzeitig muss jeder Teil eine handhabbare Größe haben, damit das System damit arbeiten kann.
Es ist wie das Schneiden eines Kuchens in gleich große Stücke, ohne die Kirschen und Nüsse in der Mitte zu zerteilen.
Der empfohlene Textsplitter in LangChain heißt RecursiveCharacterTextSplitter. Er arbeitet in drei Hauptteilen:
Texte aufteilen: Der Text wird in kleine, sinnvolle Stücke (oft Sätze) aufgeteilt.
Kombination: Diese kleinen Stücke werden zu einem größeren Stück kombiniert. Der Splitter versucht zuerst, bei Absätzen ("\n\n") zu trennen, dann bei Zeilenumbrüchen ("\n"), dann bei Leerzeichen (" ") und schließlich bei jedem Zeichen (""). Dies wird fortgesetzt, bis eine bestimmte Größe erreicht ist. Die Größe wird durch eine Funktion gemessen, die Sie selbst bestimmen können, wie z.B. die Anzahl der Zeichen.
Chunking mit Überlappung: Sobald die Größe erreicht ist, wird dieses Stück als eigener Textteil betrachtet, und ein neuer Textteil wird begonnen. Hierbei gibt es eine Überlappung zwischen den Teilen, die Sie ebenfalls steuern können. Zum Beispiel könnten Sie eine Überlappung von 20 Zeichen haben, um den Kontext zwischen den Teilen zu bewahren.
Angenommen, Sie haben einen Text mit mehreren Absätzen und möchten ihn in Stücke von maximal 50 Zeichen unterteilen. Der Text lautet:
"Das ist der erste Absatz.\n\nDas ist der zweite Absatz."
Der Splitter teilt den Text zuerst bei den Absatzenden ("\n\n") in zwei Teile:
"Das ist der erste Absatz."
"Das ist der zweite Absatz."
Da beide Teile weniger als 50 Zeichen haben, ist hier keine weitere Aufteilung erforderlich.
Nun nehmen wir einen längeren Satz: "Das ist ein sehr langer Satz, der in kleinere Teile unterteilt werden muss."
Der Splitter geht durch die Hierarchie der Trennzeichen, von Absätzen zu Zeilenumbrüchen zu Leerzeichen, und teilt den Satz in:
"Das ist ein sehr langer Satz,"
"der in kleinere Teile"
"unterteilt werden muss."
So wird der Text in handhabbare Stücke unterteilt, die die festgelegte Größenbeschränkung nicht überschreiten.
Technologie dahinter
Text Splitter: Werkzeuge, die die oben genannten Prozesse durchführen.
Beispielcode (die Inhalte der Webseite werden geteilt):
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500)
all_splits = text_splitter.split_documents(data)
Schritt 3: Text speichern
Sobald die Texte in handhabbare Stücke unterteilt sind, müssen sie irgendwo gespeichert werden, damit das System später darauf zugreifen kann. Dies ist nicht nur eine Frage des Speicherns auf einer Festplatte; die Textstücke werden in einem intelligenten Speichersystem abgelegt.
Stellen Sie sich vor, Sie haben viele verschiedene Dokumente, und Sie möchten sie in einem Ordnersystem so organisieren, dass Sie genau das finden können, was Sie brauchen, und zwar schnell. Das ist es, was dieses intelligente Speichersystem tut.
Die Informationen werden so organisiert und gespeichert, dass das System sie später schnell abrufen kann. Es ist, als ob Sie einen sehr klugen Bibliothekar hätten, der genau weiß, wo jedes Buch steht, sodass Sie es sofort finden können, wenn Sie es brauchen.
Für diejenigen, die mehr über die Technologie erfahren möchten, die diesen schnellen Zugriff ermöglicht, gibt es eine detaillierte Erklärung darüber, wie Texte in einer Form gespeichert werden, die schnelle und intelligente Suche unterstützt.
Das Speichern der Texte auf diese Weise ist ein Schlüsselschritt, um sicherzustellen, dass das System später effizient arbeiten kann, wenn es darum geht, Antworten auf Fragen zu finden.
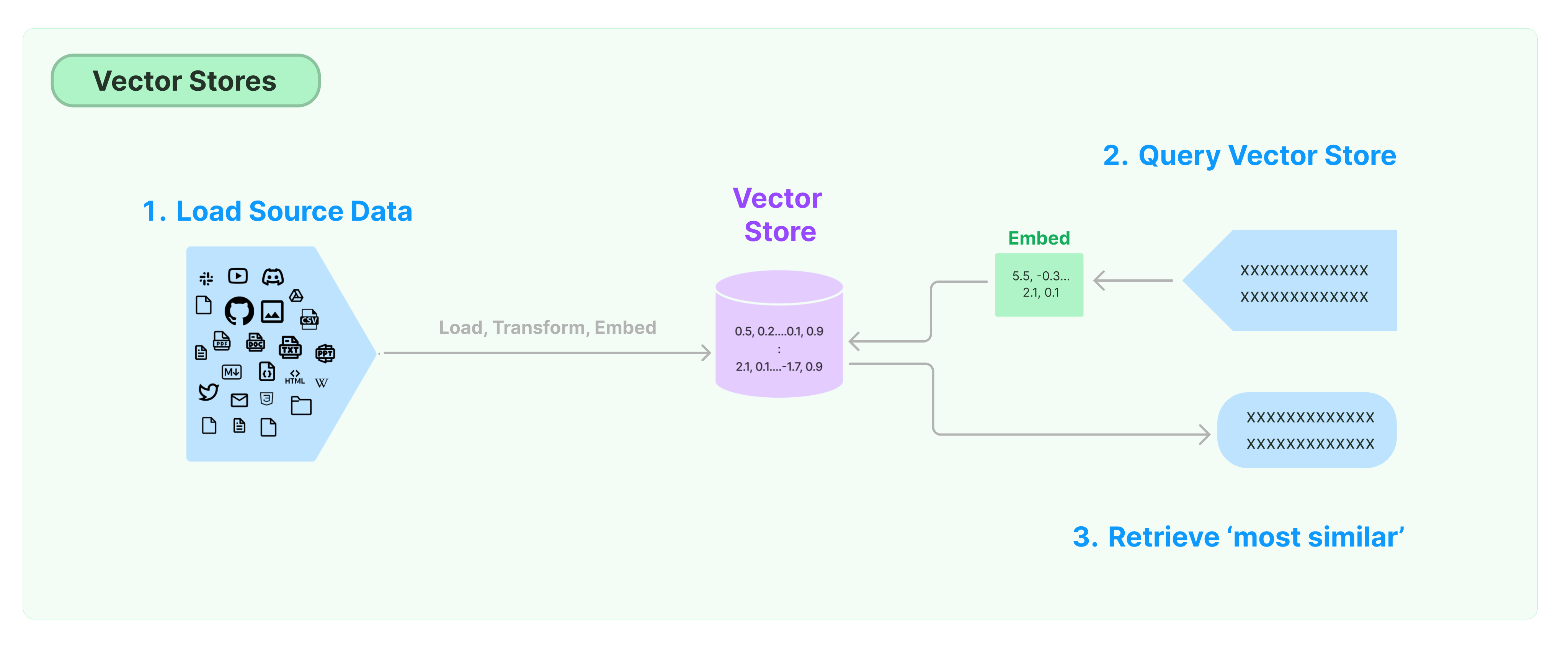
Technologie dahinter
Vectorstores und Embeddings: Diese Technologien ermöglichen es, Text in einer Form zu speichern, die die schnelle und intelligente Suche unterstützt.
Beispielcode:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAI)
Schritt 4: Relevante Informationen finden
Jetzt, wo die Texte gespeichert sind, kommt der spannende Teil: das Finden der Antworten auf Fragen. In diesem Schritt sucht das System nach Textstücken, die die Antwort auf eine gestellte Frage enthalten könnten.
Stellen Sie sich vor, Sie fragen einen erfahrenen Bibliothekar nach einem bestimmten Thema, und er führt Sie direkt zu den Büchern und Artikeln, die genau die Informationen enthalten, die Sie suchen. Das System macht das Gleiche, nur viel schneller.
Es verwendet spezielle Algorithmen, die die Ähnlichkeit zwischen der Frage und den gespeicherten Textstücken berechnen. Es ist, als ob es jedes Textstück mit Ihrer Frage vergleicht und diejenigen auswählt, die am besten passen.
Dieser Schritt ist entscheidend, denn er sorgt dafür, dass das System die relevantesten und nützlichsten Informationen findet. Es ist wie das Finden der richtigen Zutaten, bevor Sie ein Gericht kochen. Wenn Sie die richtigen Zutaten haben, wird das Endergebnis viel besser.
Technologie dahinter
Retrievers: Werkzeuge wie Vectorstores oder Support Vector Machines (SVMs), eine Art von Lernalgorithmus, die eine Ähnlichkeitsberechnung zwischen Texten durchführen.
Beispielcode:
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
Schritt 5: Antwort generieren
Nachdem das System die relevanten Textstücke gefunden hat, kommt der letzte Schritt: eine Antwort zu formulieren. Es geht nicht nur darum, die Informationen wiederzugeben, sondern sie in eine klare und präzise Antwort zu verwandeln, die Sinn macht.
Stellen Sie sich vor, Sie hätten einen Experten an Ihrer Seite, der Ihre Frage hört, die besten Bücher und Artikel durchblättert und Ihnen dann genau die Antwort gibt, die Sie brauchen. Das ist es, was das System in diesem Schritt tut.
Es verwendet fortschrittliche Sprachmodelle, die in der Lage sind, menschenähnliche Antworten zu generieren. Diese Modelle nehmen die gefundenen Informationen und formulieren sie so um, dass sie direkt auf Ihre Frage antworten. Es ist, als ob ein erfahrener Lehrer oder Fachmann die Antwort speziell für Sie geschrieben hätte.
Dieser Schritt verwandelt Rohdaten in nützliche Erkenntnisse und sorgt dafür, dass Sie genau das bekommen, was Sie von dem System erwarten: klare, präzise und verständliche Antworten auf Ihre Fragen.
Technologie dahinter
LLMs wie GPT-3.5-turbo: Diese Modelle können Textstücke in eine präzise Antwort umwandeln.
Beispielcode:
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever)
result = qa_chain({"query": question})
Schlussfolgerung
Die Integration von Large Language Models (LLMs) wie ChatGPT in Ihr Unternehmen erfordert eine sorgfältige Planung und Implementierung. Durch das Verständnis der einzelnen Schritte und der zugrunde liegenden Technologien können Sie jedoch eine leistungsstarke Lösung schaffen, die Ihr Unternehmen auf die nächste Stufe hebt.
Ob Sie eine verbesserte Kundenbetreuung, schnellere Entscheidungsfindung oder innovative Produktentwicklung anstreben – LLMs bieten die Flexibilität und Intelligenz, um Ihre Ziele zu erreichen. Die Technologien sind da, und die Möglichkeiten sind nahezu grenzenlos. Der Schlüssel liegt in der geschickten Anwendung dieser Werkzeuge, um Ihre spezifischen Unternehmensbedürfnisse zu erfüllen.
Beginnen Sie noch heute mit der Erforschung, wie LLMs die Effizienz und Effektivität Ihres Unternehmens steigern können. Mit den richtigen Strategien und dem Engagement für kontinuierliche Innovation, kann Ihr Unternehmen eine Vorreiterrolle in der digitalen Transformation einnehmen.





